上网 = “裸奔”?单凭浏览器的历史记录就能锁定你的身份


通常,网页浏览器会记录用户访问过的网站列表,即网页浏览历史记录,这对很多人来说也是特别熟悉的日常之一。
但是,如果网页浏览历史记录可以用来识别每个个体呢?我们下面要介绍的研究,恐怕会让你对这件习惯的事情有新的认识。
就在本月举行的 USENIX 会议上,Mozilla 的研究人员发现了其中的异样:他们对 5.2 万名(事先同意)的Firefox 用户在两周内的浏览历史数据集进行了分析,结果显示,48,919 份浏览资料具有可区分性,即 99% 的浏览历史是独一无二的。超过八成用户可通过浏览历史被识别身份。而且,只需要考虑 50 个最常用网站就足矣。
如此看来,尽管人类还没有成为 cyborg,但你的网页浏览记录,正在从“数字脚印”变成“互联网指纹”。
“互联网指纹”的敏感性
Mozilla 此项研究名为“Replication: Why We Still Can‘t Browse in Peace: On the Uniqueness and Reidentifiability of Web Browsing Histories[1]“ ,其实是对2012年一项研究的进一步拓展。

在 2012 年的研究中,研究者首先建立了一个测试网站,并使用 CSS 代码从 6000 个域名列表中识别出参与者访问过的网站。当时的研究结果显示,基于这 6000 个域名,参与的受试者,97%都形成了非常具有独特性的浏览历史,仅此数据就可以用来追踪确认这些参与者。
而 Mozilla 这一次研究所采用的数据则更精确,因为它收集了 5.2 万名参与者的全部浏览记录,数据包括对 66 万个独特域名的 3500 万次网站访问,也是该领域规模最大的一次研究。
参与者首先和 Mozilla 团队分享他们的浏览历史,然后,Mozilla 团队开始试验他们是否能从大量数据中重新识别出这些用户。令人惊讶的是,99%的浏览记录被发现具有独特性,能与用户“对号入座”。
有趣的是,2012年和2020年的两次研究,还证明了时代在不断“进步”:八年前,对于用户访问量最大的前50个网站,识别用户的准确率为38%,对于500个网站的数据集,准确率为70%;今天,以50个网站为基础的重新识别准确率为50%,以150个网站为基础的重新识别准确率为90%。
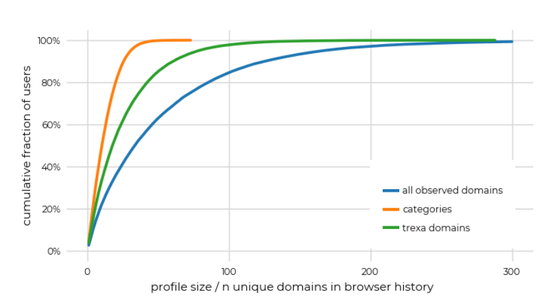
事实上,网页浏览历史的敏感性不难理解,因为用户偏好通常是固定的,一段时间的浏览习惯也会比较稳定,网页历史记录往往不会随着时间的推移而发生重大变化,而且某种程度上,它们能传达用户的丰富信息,甚至能捕捉用户的心理或用作人口统计数据。
由于网页历史记录的独特性和稳定性,在某些方面,它们确实类似于生物识别数据。
Mozilla 团队表示,“通过网页和第三方可见的浏览历史记录重新识别用户是充分可行的,而浏览历史汇总对个人隐私的潜在威胁也得到了证明”。
网页浏览记录会被明确划为“个人信息”吗?
更坏的消息是,团队观察到,众多互联网机构正无孔不入地收集这类信息,从而利用浏览记录建立用户档案或者作为标记符,在整个互联网上追踪用户及用户行为。
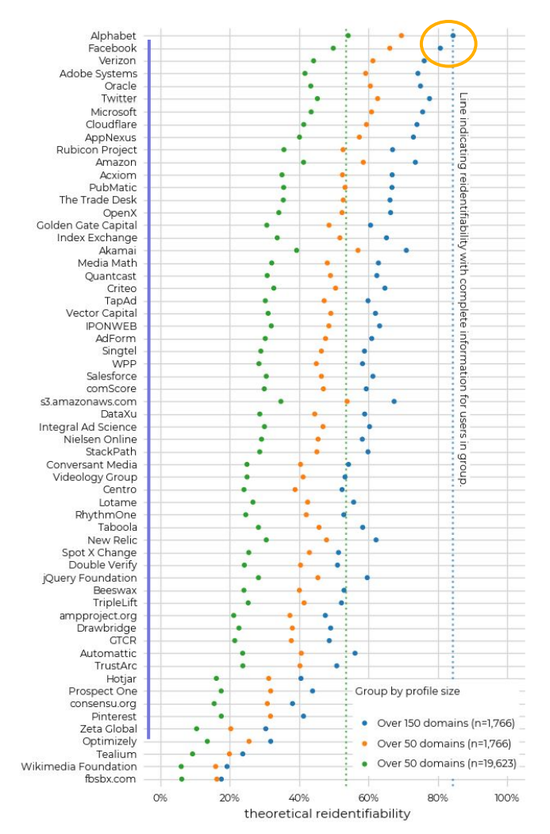
而且和 2012 年相比,现在用户的访问历史记录规模又更大了,在过去十年中,网站运营商和广告商可获得的网页浏览历史数据的数量明显增加了,几乎所有网络都会记录用户的访问历史,例如搜索引擎、社交媒体、视频网站等网络平台等,几乎都能够看到自己的浏览历史,平台则会收集、利用这些数据,以提高自身服务,并进行更精准的广告投放。像谷歌、Facebook 这样的流量帝国,处理这些信息的次数和程度肯定会更多。
隐私研究人员、2012年论文作者之一的 Lukasz Olejnik 一语道破之:这项最新研究的发现能带来更深远的影响,因为它证实了网络浏览历史所具有的可被用于牟利的属性。
如果根据这些信息有可能从许多人中识别出特定的用户,这些信息也就具有了个人数据的属性。
目前,全球最权威的数据隐私法规之一《通用数据保护条例》(General Data Protection Regulation,GDPR),给出了判断某数据信息是否属于个人数据的技术标准:
简而言之,当该数据能识别出个人时,这类数据将自动受该法规(GDPR)管辖。
而在我国,与个人数据隐私保护最直接相关的法律——《个人信息保护法》——尚未正式出台,但2019年10月发布的专家意见稿中,也已将“网络浏览历史”划入个人信息范围。
围绕这个话题,2020年国内也有一起非常典型的案例:爱奇艺的超前点播多重收费机制被其用户吴先生起诉,在败诉之后,又被指侵犯隐私,因为爱奇艺在案件庭审中提交了原告用户吴先生的观影记录,目前,对该案件的的审理还在进行中。无论最终结果如何,互联网平台的权限边界都应该退一退了。
来源:数据实战派
